ソフトセンサーの基礎理論と産業用システムアーキテクチャ
現代のプロセス産業において、製品品質の厳格な安定化とプロセス運用の最適化は企業の競争力を左右する非常に重要な要素です。
現在我々はインダストリー4.0のパラダイムの中にあり、クラウドコンピューティングやビッグデータ解析の台頭によって、プラント内には無数のセンサーが配置され膨大なデータが収集されるようになりました。(※インダストリー4.0:製造業においてAIやIoTを活用し、生産プロセスをデジタル化・自動化しようとする「第4次産業革命」のこと)
しかしながら、製品の濃度や粘度といった最終的な運用目的となる重要な品質変数の多くは、オンラインでの直接測定が技術的に困難であったり、高額な物理的分析計器による断続的な測定に依存していたりします。これらの計測器はサンプリングから結果出力までに数時間から半日程度の遅延を伴うことが多く、リアルタイムなフィードバック制御を適用する上での致命的なボトルネックとなっています。
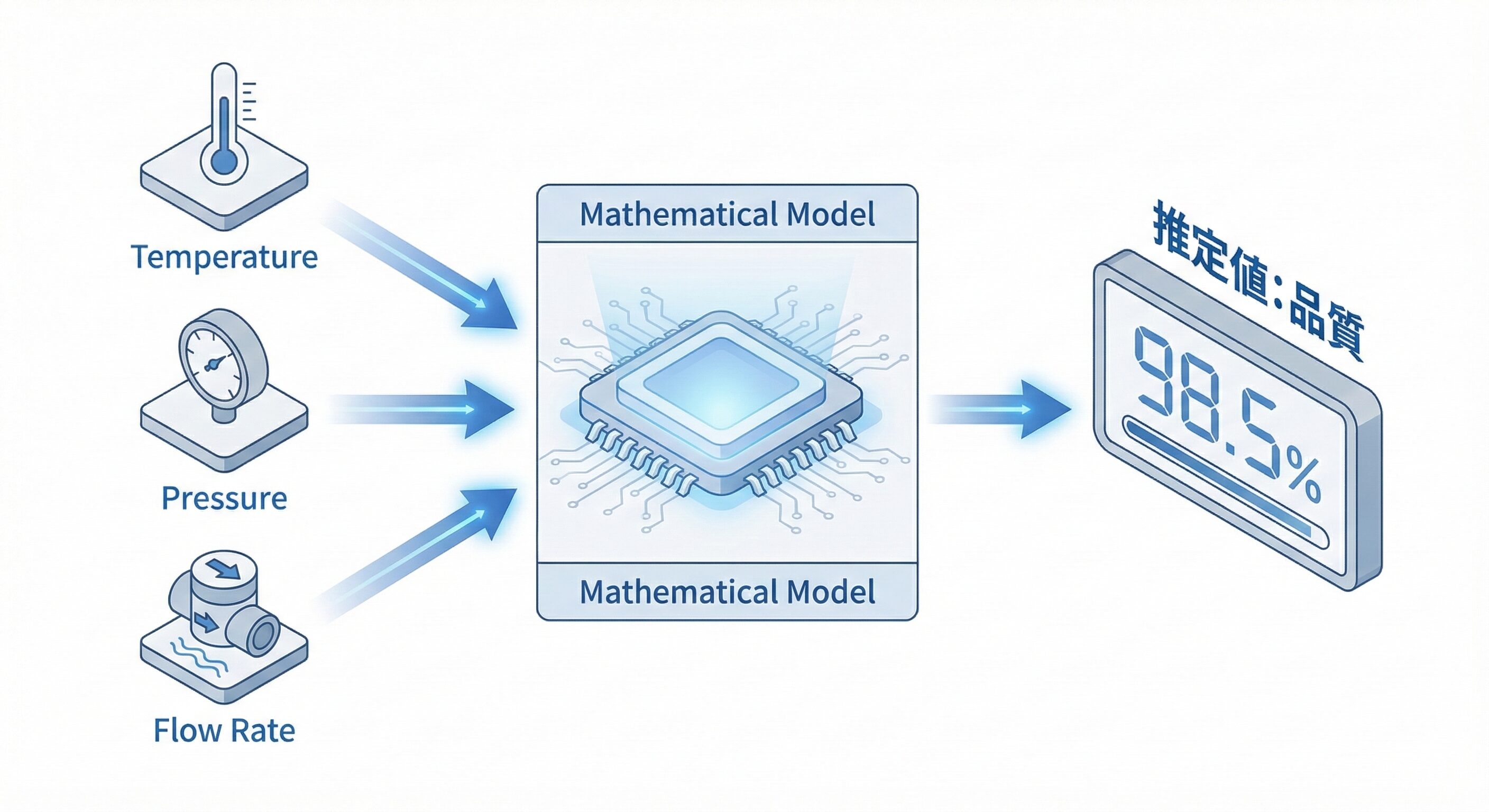
プラントにおけるソフトセンサーの概念図
このような物理的制約を打破し、計測のリアルタイム性を飛躍的に向上させる中核技術がソフトセンサーです。
ソフトセンサーは物理的なハードウェアではなく、コンピュータ上のソフトウェアアルゴリズムとして実装されます。温度計や圧力計などの測定容易なセンサーネットワークから得られる高頻度データを入力とし、数学的モデルを介して測定困難な重要変数をリアルタイムで推定します。
ソフトセンサーの数学的定式化と基本原理
数学的な観点からソフトセンサーを捉えてみましょう。プロセスから得られるソフトセンサーは以下の式のように定式化されます。
ここで、f(x)は入力変数群と目的変数の間の関係性を記述する数学的モデルを指し、epsilonはモデル化不可能なノイズや測定誤差、未観測の外部要因による変動を表します。
入力変数には温度や圧力、流量といったオンラインセンサーの連続的な指示値や操作変数が含まれます。一方の目的変数yには、実験室で分析される製品の品質データなどが該当します。プロセスの非線形性や時間遅れを含む複雑な動特性をいかに正確に近似し、未知のデータに対する予測能力を確保するかが最大の技術的課題となります。
モデル構築の3つのアプローチ
ソフトセンサーにおける数学的モデルの構築アプローチは、内部構造の透明性などに基づいて大きく3つのカテゴリに分類されます。
ホワイトボックスモデル
質量収支やエネルギー収支といった物理学・化学的な基本法則に完全に基づいて数式化されるモデルです。内部構造が完全に透明であるため解釈が容易であり、未知の運転条件に対しても論理的な予測を提供します。しかし、複雑な工業プロセスですべての現象を正確に数式化することは極めて困難であり、莫大な開発時間を要します。
ブラックボックスモデル
プロセスの物理的なメカニズムを考慮せず、蓄積されたデータのみを用いて機械学習技術などで関係性を学習するモデルです。十分なデータがあれば短期間で高精度なモデルを構築可能ですが、内部構造が不透明であり予測根拠の解釈が難しいという短所があります。また、学習データにない条件が入力されると予測精度が著しく低下する危険性があります。
グレーボックスモデル
ホワイトボックスの物理的制約とブラックボックスのデータ適合能力を統合したハイブリッドモデルです。予測精度と物理的な妥当性を両立させ、データの不足を物理法則で補完する理想的な関係を築きます。ただし、両方の手法に関する高度な知見と複雑なアーキテクチャ設計が必要になります。
物理的ハードセンサーの限界とソフトセンサーによる補完
過酷な生産環境下において、物理的なハードセンサーは高額な導入・維持コストの問題を抱えています。また、インライン測定が不可能な場合はオペレーターが手動でサンプルを採取して実験室で分析する必要があり、大きな遅延が発生します。この遅延は異常発生時の対応を遅らせる深刻なリスクとなります。さらに、過酷な環境ではセンサープローブの劣化や突発的な故障も頻発します。
ソフトセンサーを導入することで、高価な分析計の新規購入を回避し、ラボでの分析頻度を減らすことで運用コストを劇的に削減できます。数秒から数分単位での高頻度な予測値を提供するため、モデル予測制御などの高度な制御へのシームレスな統合が実現します。重要なハードセンサーが故障した際にはその出力を代替し、プラントの予期せぬダウンタイムを回避することも可能です。
リアルタイム推論を支えるシステムアーキテクチャ
ソフトセンサーを単なる解析ツールにとどめず、実際のプラントで稼働する推論エンジンとして実装するためには、プラントのインフラストラクチャに対する深い理解が必要です。
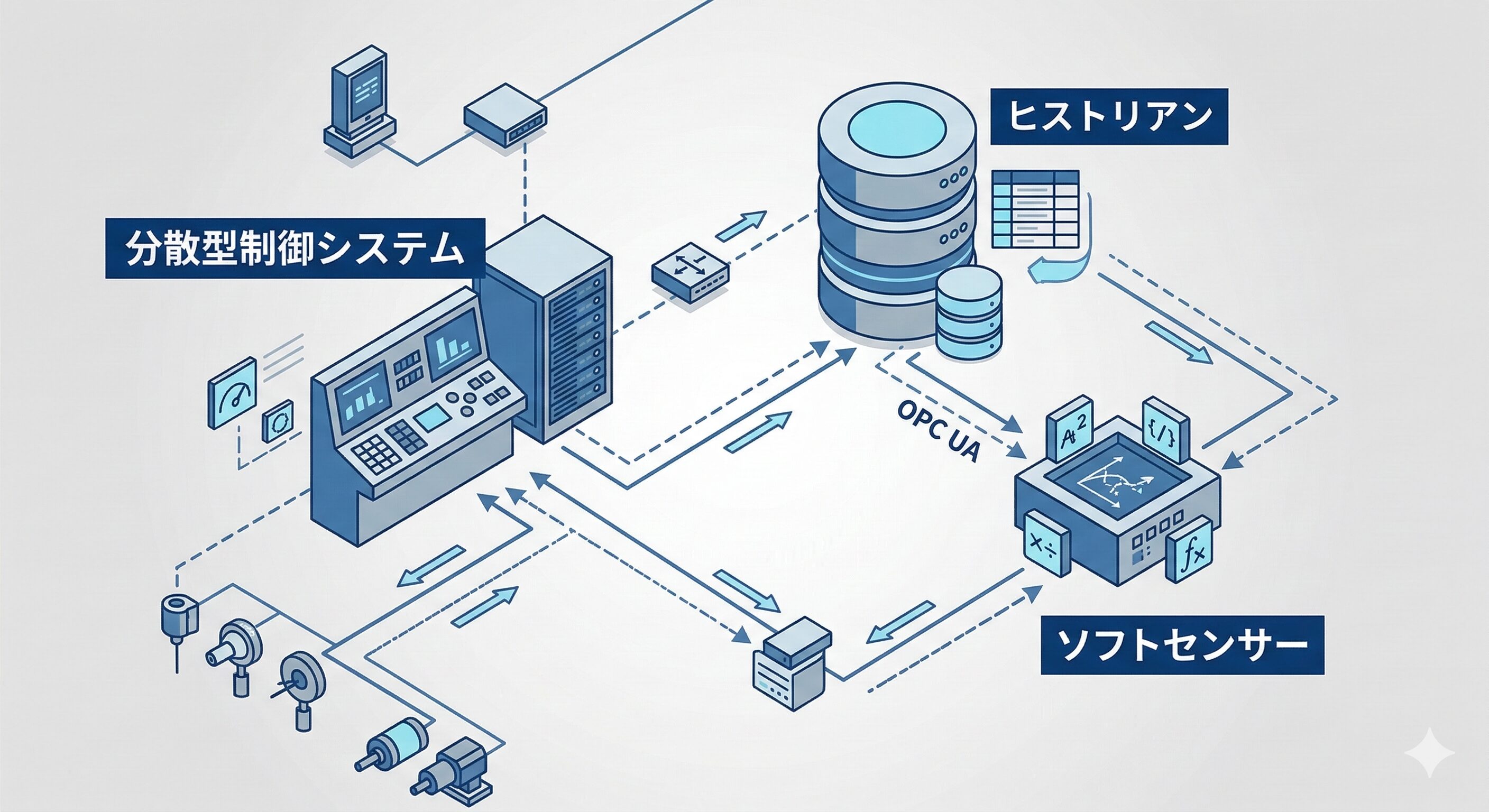
DCSを中心とした産業用システムアーキテクチャのデータフロー
制御の最前線となるのがPLCやDCSです。
DCSは大規模な連続プロセスの監視・制御に特化しており、プロセス全体に分散されたアーキテクチャによって高い可用性を確保しています。ソフトセンサーのアーキテクチャにおいて、DCSは推論に必要なプロセス変数を一元的に管理する巨大なデータハブとして機能します。
過去から現在に至るまでの膨大なデータを効率的に蓄積するのがプロセスデータヒストリアンです。ヒストリアンは時系列データに特化しており、独自の圧縮技術を用いて微小変動を除外しながら何万もの測定ポイントのデータを長期間保存します。また、ネットワーク障害が発生してもローカルバッファにデータを一時保存し、接続回復後に欠損なく補完転送するメカニズムを持っています。
これらの異なるシステム間でセキュアにデータを転送する国際通信規格がOPC UAです。
OPC UAはOSに依存せず、暗号化通信による強固なセキュリティを提供します。単なる数値だけでなく、そのデータに豊かなコンテキストを付与する機能を持っているため、プラント内のデータ構造を動的に解釈して効率的に処理することが可能になります。
(※PLC:工場の機械をあらかじめ決めた順番や条件で動かすための、現場用コンピュータのこと)
ソフトウェア開発ライフサイクルに基づく実装戦略
ソフトセンサーは継続的な運用と保守を前提としたソフトウェアであり、ソフトウェア工学における開発ライフサイクルの概念を適用した厳密なフェーズ管理が要求されます。
要件定義とプロジェクト計画 :運転員やデータサイエンティストが協働し、推定すべき品質変数や許容される予測誤差の閾値を定義します。対象プロセスの動特性を評価し、要件仕様を策定します。
データ収集とインフラストラクチャ評価 :ヒストリアンなどに蓄積されている過去の履歴データを抽出し、オンラインデータとラボの分析データを突合させます。欠損値やノイズをいかに包括的に捕捉するかが求められます。
データ前処理とシステム設計 :収集されたデータから外れ値の除去や標準化を実施します。さらに、変数間の強い相関を回避し、予測に寄与する変数を抽出する特徴量選択を行います。
モデル構築と実装 :プロセスの特性に最適なアルゴリズムを選択し、ハイパーパラメータ(人間が手動で設定しなければならない「モデルの微調整用つまみ」のような数値のこと)の調整を行います。汎化性能を確保し、実行環境に収まる計算負荷で設計することが鍵となります。
モデル解析と検証 :テストデータを用いて交差検証(手持ちのデータを分割して「学習用」と「テスト用」を入れ替えながら何度も検証し、モデルの信頼性を確かめる手法)を行い、ラボ分析値と比較ベンチマークを実施します。モデルが信頼できる適用領域を定義し、フェイルセーフ機構を設計します。
システムへのデプロイ: 検証を通過したモデルを生産環境に統合します。最初は予測値を画面に表示するのみのオフラインモードで安全性を確認し、その後に閉ループ制御へフィードバックするオンラインモードへと段階的に移行します。
運用保守と継続的改善 :プロセス特性の経年変化に伴い、予測精度が低下する概念ドリフトと呼ばれる現象が発生します。定期的に予測値とラボデータを比較し、乖離が大きくなった場合にはモデルの再学習を実行する仕組みを構築することがインダストリー4.0時代における真の要件となります。
データ品質を極限まで高める前処理と特徴量エンジニアリング
産業用ソフトセンサーの精度を最終的に決定づけるのは、実は高度なAIアルゴリズムそのものではなく、そこに入力されるデータの品質です 。
実際のプラントから得られるデータには、センサーの劣化、突発的な電気ノイズ、時間遅れ、バッチ間の時間不一致など、無数の阻害要因が含まれています 。これらを未処理のまま入力すると、モデルは見せかけの相関を学習してしまい、実運用に耐えられません 。ここでは、データ品質を極限まで高めるための技術を詳しく見ていきましょう 。
産業データの浄化:外れ値検知とノイズ平滑化
プラントデータには、通信エラーなどによるスパイク状の「外れ値」と、プロセスが持つ高周波の「ランダムノイズ」が混在しています 。
外れ値の検知には、従来の3シグマ法(データのばらつき具合を見て、平均から大きく外れた値を「異常値」として機械的に見つけ出す手法)に代わり「Hampel(ハンペル)フィルタ」が標準的に用いられます 。
巨大な外れ値が混入すると平均値や標準偏差自体が歪んでしまうマスキング効果を防ぐため、Hampelフィルタは平均値の代わりに「中央値」、標準偏差の代わりに「中央値絶対偏差(MAD)」を使用します 。
一定幅のウィンドウ内のデータからMADを算出し、中心データと局所中央値の差が推定標準偏差の一定倍数を超えた場合のみ外れ値と判定します 。近年では、毎回のソート計算を省く「修正MAD」によって計算量を劇的に削減し、リアルタイム処理への適用性が高まっています 。
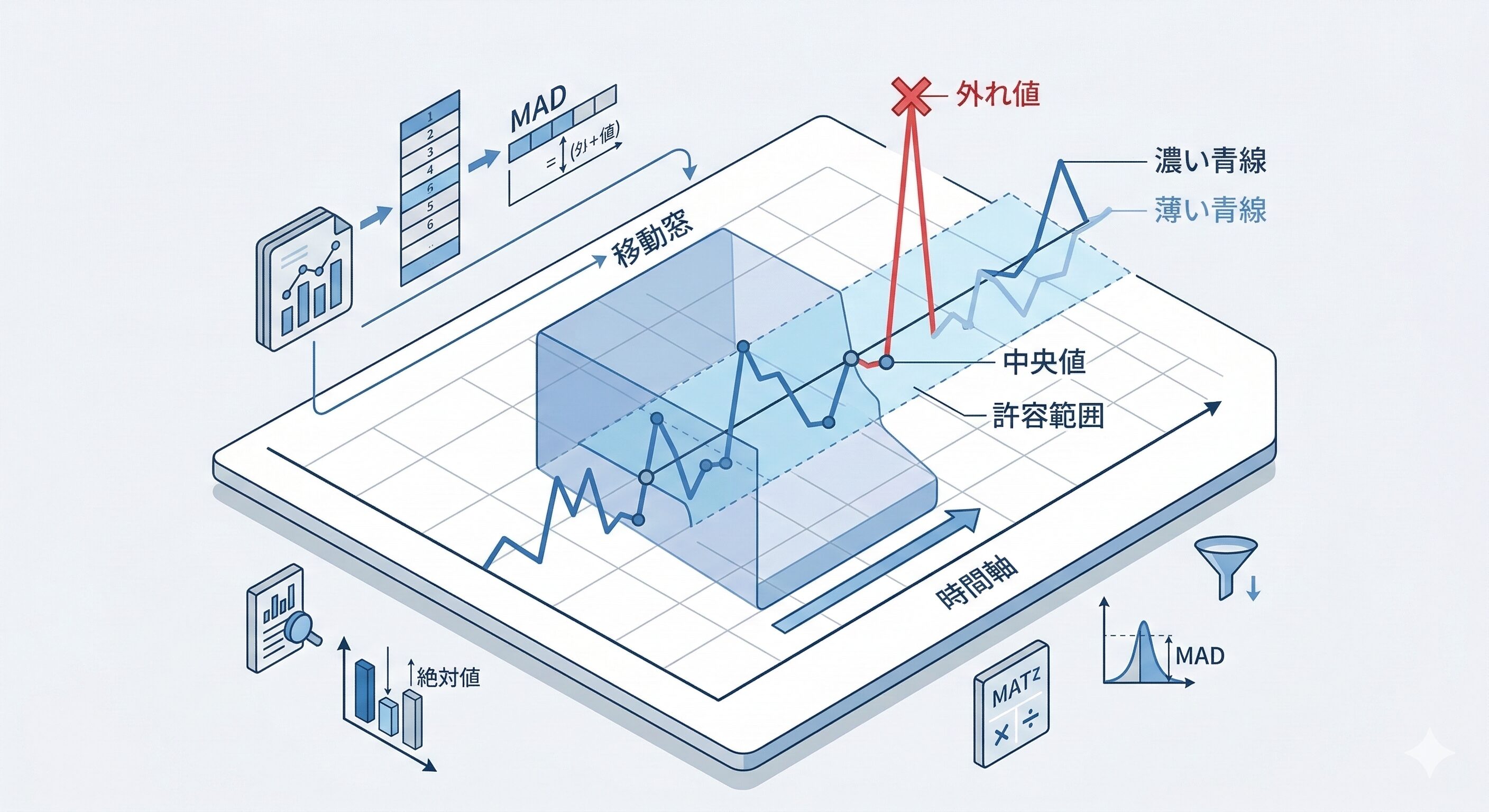
Hampelフィルタによる外れ値除去とMADの概念図
次にランダムノイズの平滑化ですが、単純な移動平均ではピークの形状が鈍るという情報損失が起きます 。これを解決するのが「Savitzky-Golay(SG)フィルタ」です 。
SGフィルタは、ウィンドウ内の局所データに対して最小二乗法(バラバラに分布しているデータ点を通る「最もそれらしい直線や曲線」を、誤差が最小になるように引く数学的な計算方法)で低次多項式を適合させ、ピークの高さや幅を歪めることなく滑らかなデータを出力します 。さらに、事前に計算した畳み込み係数との積和演算だけで済むため計算コストが低く、平滑化と同時にノイズを増幅させずに微分値まで直接算出できるという強力な特長を持っています 。
予測残差の高次モーメント最適化による未知変動への適応
データ浄化後、回帰モデルの学習では通常「平均二乗誤差(MSE)」を最小化します 。しかし、実際のプラントデータは大部分が安定した「定常状態」であり、異常を示す「逸脱状態」はごく一部です 。MSEの最小化だけでは、モデルは定常状態の微小な誤差を消すことに集中し、いざプロセスが急変動した際に追従できなくなってしまいます 。
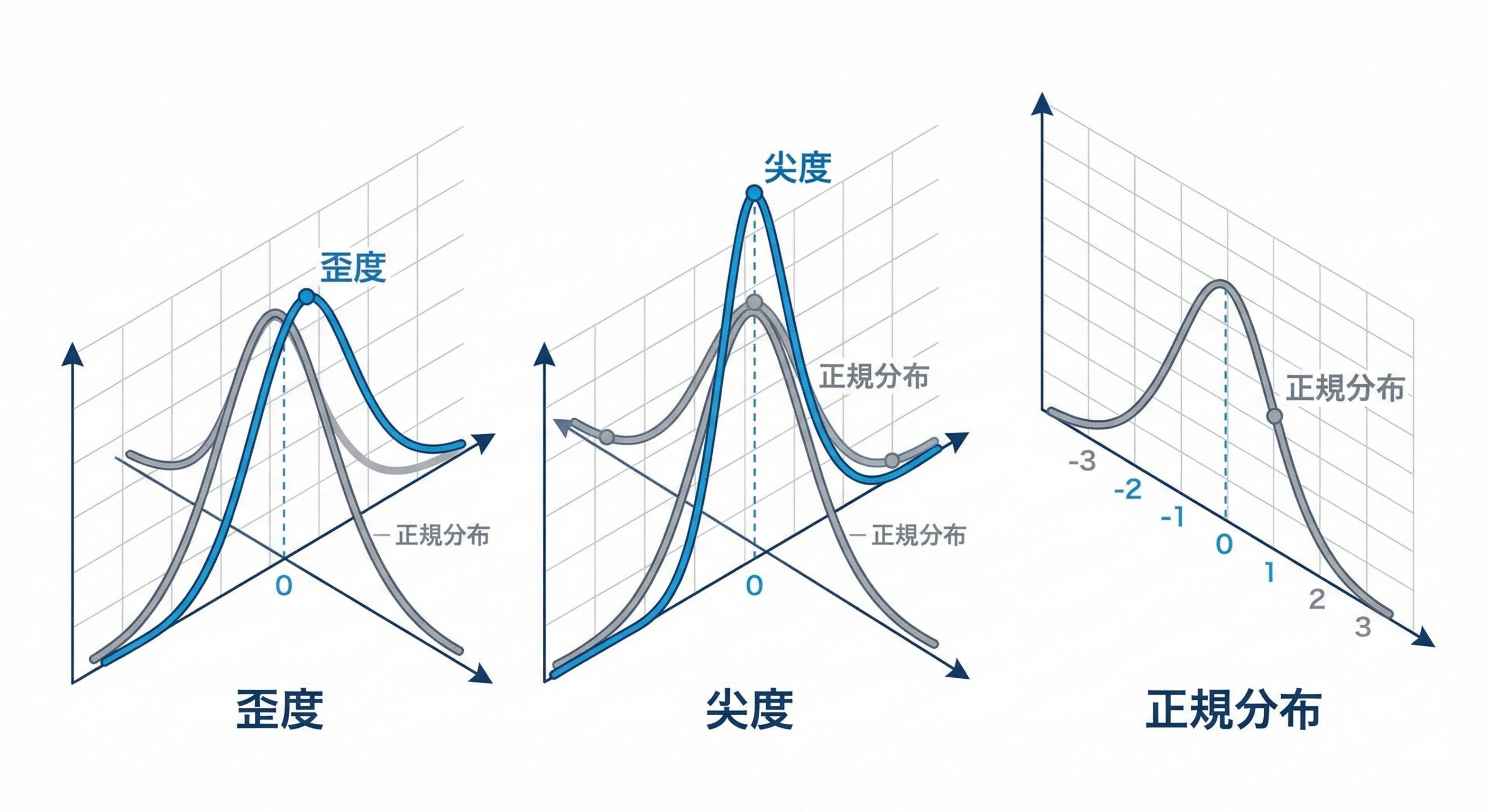
予測残差の分布における歪度と尖度の違い
そこで、予測残差の分布形状そのものを最適化する手法が重要になります。理想的なモデルの予測残差は完全な正規分布(純粋なホワイトノイズ)になります 。正規分布からの逸脱を測る指標として、誤差の非対称性を示す「歪度(Skewness)」と、誤差分布の裾の重さや鋭さを示す「尖度(Kurtosis)」を損失関数に組み込みます 。
全体の誤差(MSE)を減らしつつ、歪度を0、尖度を3に近づけるように最適化することで、定常状態の過学習を防ぎ、未知の変動への堅牢性をアルゴリズムの深層から強制することが可能になります 。
バッチプロセスの時間軸同期:可変プロセス長問題の克服
連続プロセスとは異なり、製薬や特殊化学品などのバッチプロセスでは「可変プロセス長」という深刻な問題が発生します 。
オペレーターの調整などにより、同じ製品を作っていてもバッチごとに全体の運転時間が異なり、反応ピークのタイミングがバラバラになる現象です 。多変量解析モデルに入力するためにはデータの時間軸を同期させる必要がありますが、単にデータを引き延ばすとプロセスの動的な特徴が破壊されてしまいます 。
ここで力を発揮するのが「指標変数(IV)」によるアプローチです 。
横軸を経過時間ではなく、例えば「累積原料供給量」といったプロセス進捗を直接表す物理量に変換することで、時間軸の歪みを解消します 。さらに進化形である「IVopt(最適指標変数)」手法は、サロゲート最適化を用いてバッチを自動でフェーズ分割し、品質予測誤差が最も小さくなる指標変数をフェーズごとにデータ駆動で探索します 。
これにより、動的時間伸縮法(DTW)のような膨大な計算コストを抑えつつ、極めて高い予測精度を実現できます 。
ターケンスの定理に基づく時間遅延因果推論
プラント内の変数間には、流体の移動や反応進行に伴う「物理的な時間遅れ」が存在します 。同一時間軸上での相関分析では、この遅れを見落として重要な変数を除外したり、偽の相関を拾ってしまったりします 。
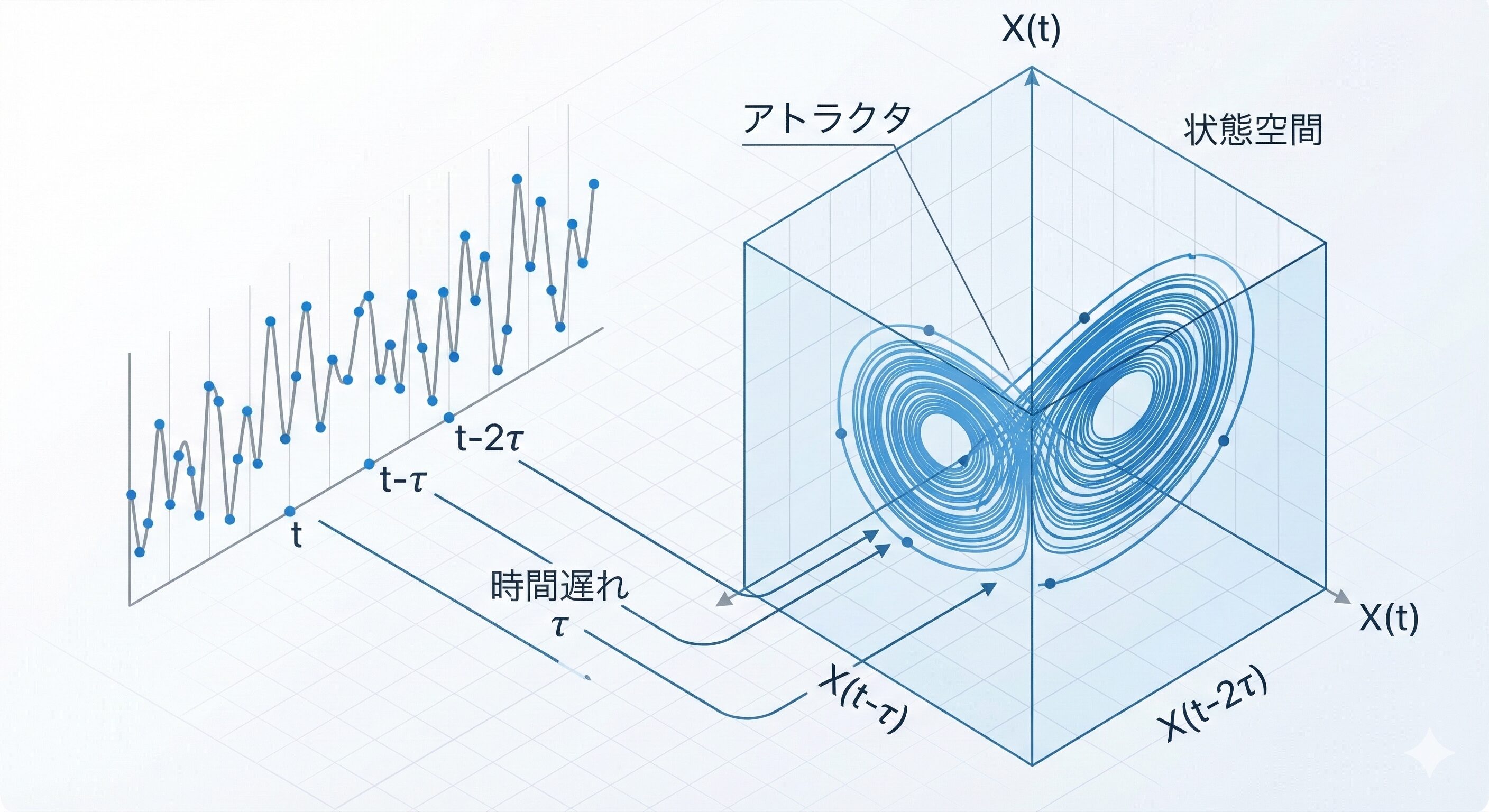
ターケンスの埋め込み定理と状態空間再構成の概念図
これを解決する数学的基盤が「ターケンスの埋め込み定理」です 。
これは、ある変数Xが変数Yに因果関係を持つなら、Xの本質的な情報はYの過去から現在に至る履歴の中に記憶(エンコード)されている、という概念です 。これを応用した「時間遅延収束クロスマッピング(TDCCM)」は、状態空間を再構成して変数間の因果関係と具体的な物理的遅延時間を特定します 。
さらに、連鎖的な影響を排除して直接的な因果パスのみを抽出する「TDPCM」を組み合わせることで、見せかけの相関を完全に排除し、真の因果の連鎖を明らかにできます 。
CARS-PLSによる最先端の変数選択アルゴリズム
データの前処理と因果の特定が終わっても、数百に及ぶ変数をすべてモデルに入れると「次元の呪い(扱う変数の種類を増やしすぎると、計算が複雑になりすぎて逆に正解が見つからなくなる現象のこと)」や「多重共線性(入力変数の中に「似たような動きをする変数」が混ざっている状態で、これがあると計算が不安定になり予測精度が落ちる)」により汎化性能が低下します 。必要十分なキー変数のみを抽出する変数選択が不可欠です 。
現在、最も傑出したパフォーマンスを示すのが「CARS-PLS(競争的適応再重み付けサンプリング)」アルゴリズムです 。これはダーウィンの進化論の「適者生存」を数理化した手法です 。モンテカルロサンプリングでモデルを構築し、回帰係数の絶対値が大きい変数を「適合度が高い」と評価します 。
指数関数的減少関数(EDF)によって徐々に変数の総数を減らしながら、ルーレット選択のように競争的に変数を抽出するプロセスを繰り返します 。最終的に交差検証で最も誤差が小さくなる変数の組み合わせを生き残らせることで、単なる予測精度の向上だけでなく、化学的・物理的要因に直結する解釈可能なキー変数をピンポイントで特定することができます 。
このように、データの浄化から時間同期、因果推論、変数選択に至る前処理と特徴量エンジニアリングは、プロセスの不確実性を機械学習が理解できる形に翻訳する極めて重要なエンジニアリング作業なのです 。
回帰アルゴリズムの進化とアンサンブル・転移学習の最前線
前回のステップで極限まで浄化され、時間軸が同期され、真に重要な変数だけが抽出されたデータは、いよいよソフトセンサーの心臓部である推論エンジンへと送り込まれます。この推論エンジンの役割は、入力されたデータから目的変数をリアルタイムに計算する回帰モデルです。
しかし、現代の複雑なプラント動特性をたった一つの数式やアルゴリズムで完全に表現することは不可能です。ここでは、基礎となる回帰アルゴリズムの特性から、複数のモデルを協調させるアンサンブル学習、そしてデータ不足を補う転移学習の最前線までを解説します。
基礎回帰アルゴリズムの数理的特性と限界
ソフトセンサーの歴史は、アルゴリズムの進化の歴史でもあります。現場でよく使われる代表的なアルゴリズムには、それぞれ明確な長所と致命的な短所が存在します。
まずは歴史が古く、現在でも化学プラントで絶対的な信頼を得ているPLS(部分的最小二乗法)です。PLSは入力変数と目的変数の共分散を最大化するように潜在変数を抽出する線形モデルです。多重共線性に極めて強く、少ないデータでも安定したモデルが作れるのが特徴ですが、プロセスが持つ本質的な非線形性(温度上昇に伴う反応速度の指数関数的増加など)を表現できないという限界があります。
非線形性を克服するために導入されたのがANN(人工ニューラルネットワーク)です。人間の脳神経回路を模したANNは、隠れ層を持つことであらゆる複雑な非線形関数を近似できる強力な能力を持っています。しかし、パラメータ数が多いため過学習(手元の過去データに合わせすぎてしまい、新しいデータが来たときに予測が外れてしまう状態)を起こしやすく、また内部構造がブラックボックス化するため、予測結果に対する物理的な解釈が極めて困難になります。
これらに対し、少ないサンプル数でも高い汎化性能(学習に使っていない「未知のデータ」に対しても、正しく予測できる能力のこと)を発揮するのがSVR(サポートベクター回帰)です。SVRは許容誤差の範囲内(チューブ)にできるだけ多くのデータを収めつつ、モデルの複雑さを抑えるマージン最大化という概念を用います。さらに、不等式制約を等式制約に変更して計算負荷を劇的に下げたLSSVR(最小二乗SVR)は、オンラインでのリアルタイム学習に適しています。
しかし、いかに優秀なアルゴリズムであっても、単一のモデルでは広大な運転領域のすべてにおいて高い精度を維持することはできません。ある領域ではPLSが強く、別の領域ではSVRが強いというように、得意分野が分かれるのが現実です。
スタッキングアーキテクチャによる弱点の相互補完
単一モデルの限界を突破するために考案されたのが、複数のアルゴリズムを統合するアンサンブル学習です。中でも強力なアプローチがスタッキングと呼ばれる階層的なアーキテクチャです。
スタッキングでは、まず第1段階としてPLS、ANN、LSSVRなどの性質の異なる複数のアルゴリズム(ベース学習器)を並列に学習させます。それぞれのモデルは同じ入力データに対して独自の予測値を出力します。次に第2段階として、これらの予測値を入力として最終的な予測を行う別のモデル(メタ学習器)を配置します。
この構造の優れた点は、各ベース学習器の弱点をメタ学習器が自動的に補完してくれることです。例えば、ある運転条件ではANNの予測が暴走しがちであることをメタ学習器が学習していれば、その条件が来た際にはANNの意見を無視し、安定しているPLSやLSSVRの意見を重視して最終結論を出します。
このように、多様な視点を持つ専門家の意見を集約して最適な判断を下す合議制のシステムを作り上げるのがスタッキングの神髄です。
混合ガウスモデルとベイズ推論を用いた位相分割アンサンブル
実際のプラントは、スタートアップ時、定常運転時、負荷変更時、シャットダウン時など、複数の異なる動作状態(位相)を持っています。これを一つの巨大なモデルで表現しようとすると、境界付近での予測精度が著しく低下します。そこで、データを位相ごとに分割し、それぞれに特化した局所モデルを構築する局所的アンサンブル学習が有効になります。
ここで活躍するのが混合ガウスモデル(GMM)です。GMMは、複雑なプラントデータの分布を、複数の正規分布(ガウス分布)の足し合わせとして数学的にモデル化します。これにより、データ空間を自動的かつ滑らかに複数の位相クラスターに分割することができます。分割された各クラスターに対して、それぞれ個別のPLSやSVRモデル(局所モデル)を構築します。
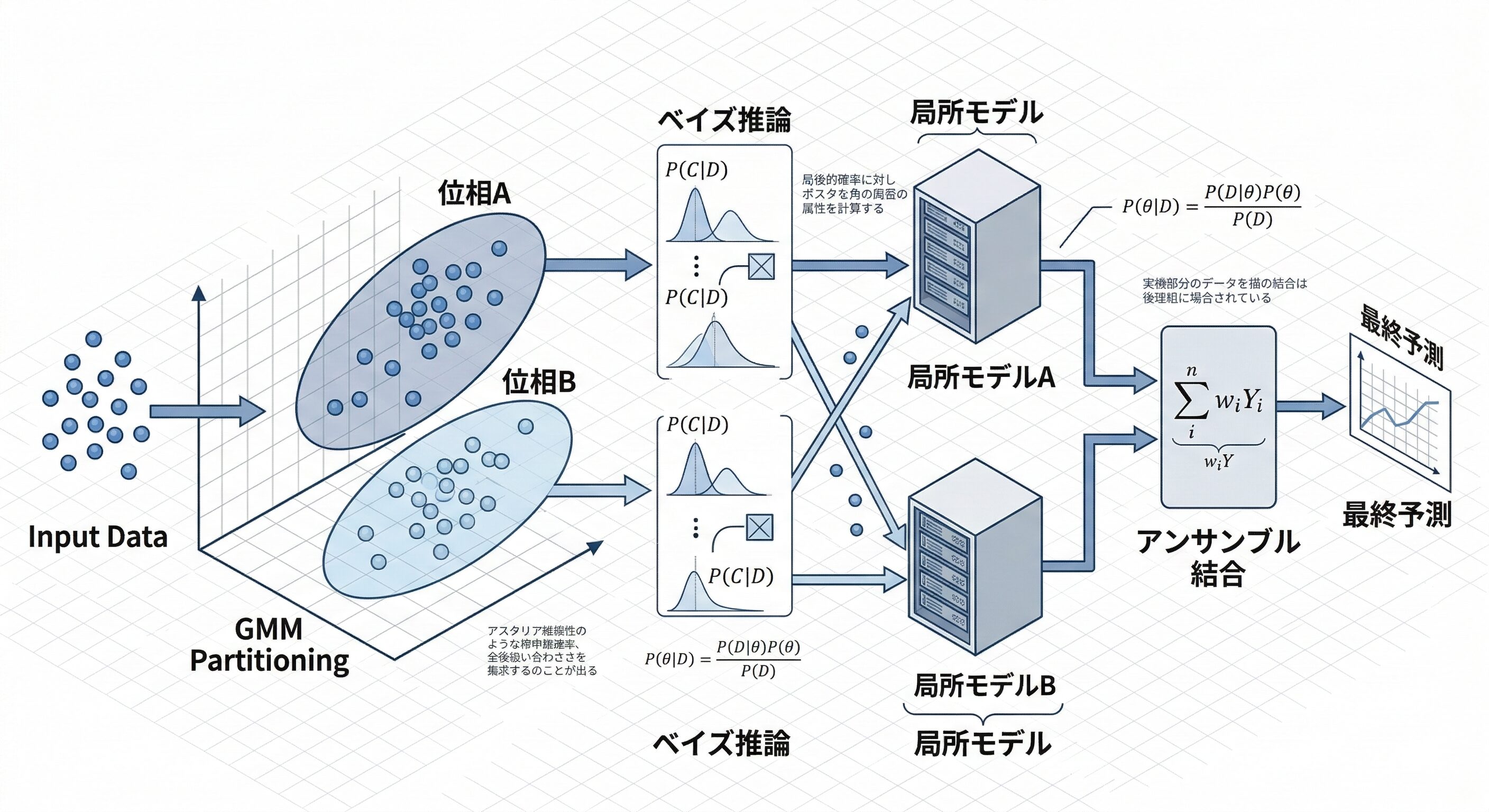
GMMとベイズ推論を用いた位相分割アンサンブル学習の概念図
オンライン推論のフェーズでは、新しいデータが入力されると、まずGMMがそのデータがどの位相に属するかを計算します。このとき、単に一つの位相に割り当てるのではなく、ベイズ推論を用いて「位相Aである確率が70%、位相Bである確率が30%」というように事後確率を算出します。そして、各局所モデルが出した予測値をこの事後確率で重み付けして足し合わせることで、最終的な予測値を出力します。
これにより、運転状態が切り替わる過渡期においても、予測値が急激に飛ぶことなく滑らかに追従することが可能になります。
マルチグレード生産を救う転移学習と負の転移の回避
現代の化学産業では、消費者の多様なニーズに応えるため、単一の設備で複数の異なる製品を切り替えて生産するマルチグレード生産が増加しています。ここで深刻な問題となるのがデータ不足です。長年生産している旧グレード(ソースドメイン)には豊富なデータがありますが、新しく導入した新グレード(ターゲットドメイン)はデータが圧倒的に少なく、高精度な推論モデルをゼロから構築することができません。
この課題を根本から解決するのが転移学習です。転移学習は、ソースドメインで培った知識をターゲットドメインに移植(転移)することで、少ないデータでも即座に高精度なモデルを構築する技術です。
ソフトセンサー分野で近年注目を集めているのがFEDA(Frustratingly Easy Domain Adaptation)という手法です。その名の通り非常にシンプルな構造でありながら絶大な効果を発揮します。FEDAは、入力データの変数を元のまま使うのではなく、全ドメインに共通する特徴空間、ソースドメイン固有の特徴空間、ターゲットドメイン固有の特徴空間の3つに拡張(コピーしてパディング)するだけで、異なるドメイン間の知識の共有と分離を数学的に実現してしまいます。

転移学習における知識転移とFEDAの構造
しかし、転移学習には負の転移という恐ろしい罠が潜んでいます。ソースとターゲットのプロセス特性が大きく異なる場合、無理に知識を転移させると、かえって新グレードの予測精度を破壊してしまう現象です。先輩の古い経験が、新しい職場で全く通用せず混乱を招くのと同じです。
負の転移を回避するためには、知識を転移する前にドメイン間の類似度を定量的に評価しなければなりません。よく用いられる指標がMMD(最大平均差異)です。ソースとターゲットのデータ分布の距離をMMDで計算し、類似度が高い場合にのみ転移学習を実行する、あるいは類似した過去のバッチデータだけを自動選択して知識を抽出する適応的なゲーティング機構を設けることが、実運用において極めて重要となります。
回帰アルゴリズムは単一モデルからアンサンブル、そしてドメインの壁を越える転移学習へと進化を遂げました。しかし、どれほど高度なモデルを構築しても、物理的なプラントが持つ避けられない宿命が待ち受けています。それが経年劣化によるプロセスの変化です。
概念ドリフトへの適応とモデルの継続的な保守・運用
ソフトセンサーは開発時のオフライン評価でどれほど高い予測精度を示しても、実際の稼働環境で時間が経過するとその性能が著しく劣化する宿命にあります 。
この原因は、プロセスが本質的に持つ非定常性にあります 。触媒の失活や配管の汚れ、外部環境の変化などにより、プロセスの物理的・化学的特性は絶えず変化しています 。劣化を引き起こす主要な要因は、入力変数と目的変数の根本的な関係性が変化する「概念ドリフト」と、計測器自体が異常値を出力する「ハードウェアセンサーの故障」の2つに大別されます 。
概念ドリフトの4分類と深刻度の定量化
概念ドリフトは、入力と出力を結びつける物理法則や因果関係のマッピングそのものが変質する現象です 。産業プロセスにおけるドリフトは、発生速度や周期性に基づき、以下の4つに分類されます 。
突発的ドリフト:運用条件の急激な変更などで関係性が非連続的かつ瞬間的に遷移する現象です 。
漸進的ドリフト:触媒の緩やかな失活などにより、古い概念と新しい概念が混在しながら徐々に移行する現象です 。
増分ドリフト:配管の汚れや摩耗などにより、状態が微小なステップで一方向に連続変化する現象です 。
再発的/季節的ドリフト:季節変動や製品切り替えにより、過去の概念が循環的に再び現れる現象です 。
モデルを永続的に維持するためには、これらの変化の深刻度を正確に定量化する必要があります 。最新のシステムでは、コルモゴロフ・スミルノフ統計量(KS検定)、Wasserstein距離、Jensen-Shannonダイバージェンスという3つの統計的距離尺度を統合して「ドリフト深刻度スコア」を算出します 。この際、産業データ特有のノイズによる誤検知を防ぐため、分位点変換という前処理技術を適用することが極めて重要です 。
算出されたスコアに基づき、システムは3段階の適応アクションを実行します 。軽度の場合は監視のみを継続し、中等度の場合はパラメータのみを微調整するインクリメンタル更新を行い、重度の場合は最新と過去の重要データを結合してゼロからフル再学習を行います 。
AANNによるハードウェアセンサーの自己修復
センサー自体の故障は、物理的な現実は変わっていないにもかかわらず誤ったデータが送り込まれる事態を引き起こします 。これに対処するため、自己連想ニューラルネットワーク(AANN)を用いたアーキテクチャが標準となっています 。
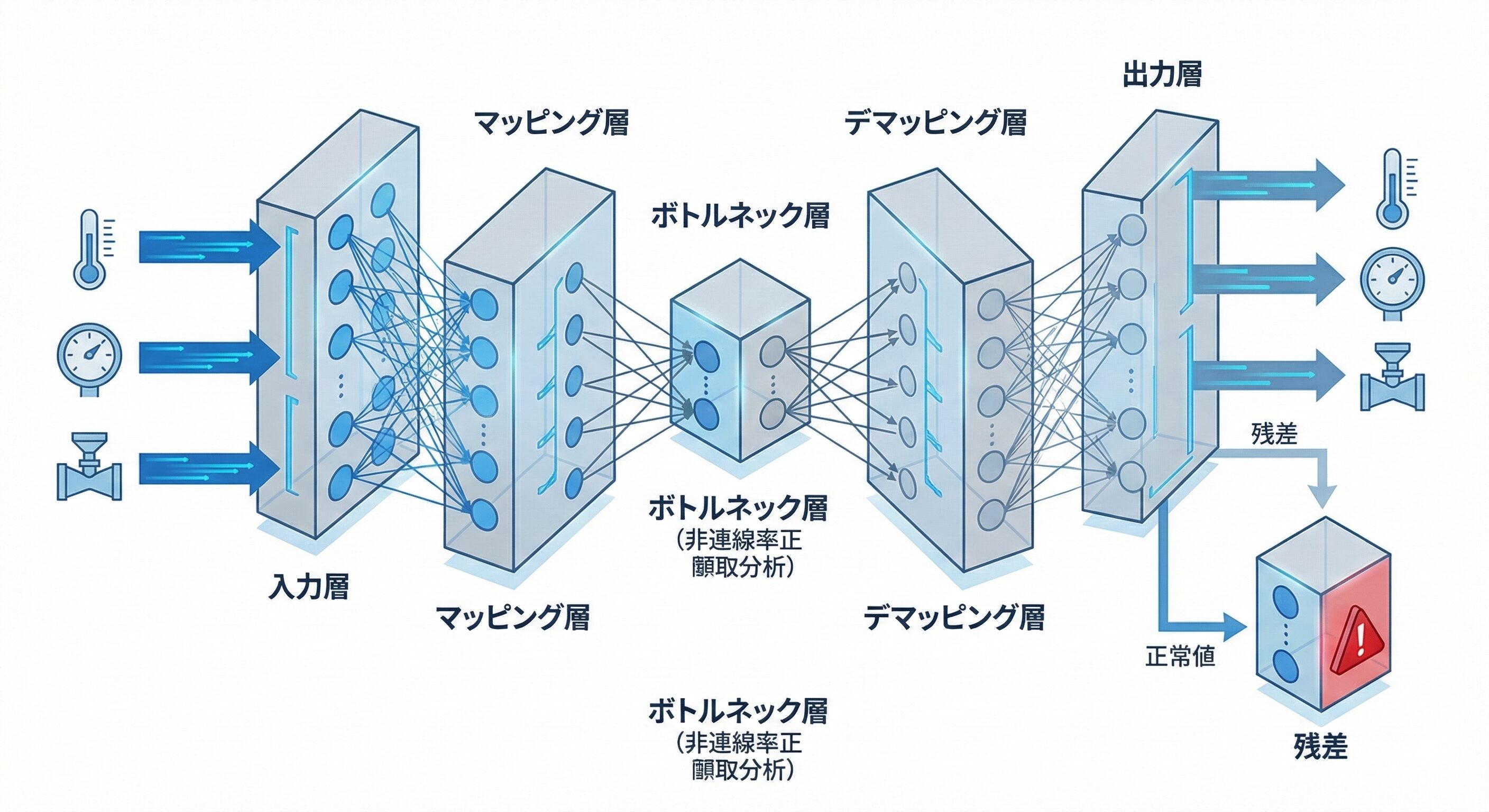
AANNの5層ボトルネック構造による非線形主成分分析
AANNは入力層から出力層までの5層で構成され、中央にノード数を絞ったボトルネック層を持ちます 。この構造により、ネットワークは単なる入出力のコピーではなく、変数間の本質的な相関関係を強制的に学習します 。稼働中にセンサーが異常値を示すと、正常な相関パターンから逸脱するため、入力値と再構築値の間に大きな残差が生じます 。
この残差を二乗予測誤差(SPE)として定量化し、限界値を突破した瞬間に異常兆候として検知します 。さらに、拡張型AANN(E-AANN)を用いることで、SPEを最小化するような最適化探索を行い、故障したセンサーの真の値を推定してリアルタイムで正常な値に置き換える自己修復が可能になります 。
再帰的アルゴリズムとJIT学習の高度化
連続的にデータを学習する再帰的PLS(RPLS)は、過去の膨大なデータによってモデルが硬直化する「データ飽和」の問題を抱えています 。これを克服するため、過去の記憶を減衰させる忘却係数や、最新の一定期間のデータのみを保持する移動窓法(MW)が導入されてきました 。
さらに、センサーの緩やかなゼロ点ドリフトなどのベースライン変動を排除するため、時間的な差分値を訓練データとして用いる時間差分移動窓再帰的PLS(TD-MW-RPLS)が考案され、変数間の真の動的相関関係のみを学習できるようになりました 。
一方、現在の状態に最も類似した過去のデータのみを抽出してその場限りの局所モデルを作るジャストインタイム(JIT)学習も進化しています 。変数間の強い相関を無視してしまうユークリッド距離の欠点を克服するため、共分散行列を組み込んで相関構造を補正するマハラノビス距離が標準的に採用されています 。また、バッチごとのプロセス時間のばらつきに対しては、動的時間伸縮法(DTW)を用いて時系列波形を非線形に同期させることで高精度な予測を実現しています 。
深層学習における破滅的忘却と継続学習
近年導入が進む深層学習モデル特有の致命的な課題が「破滅的忘却」です 。新しいデータストリームのみで学習を行うと、過去の正常状態や異なるグレードの生産条件で形成された貴重な知識が上書きされ破壊されてしまいます 。需要変動などで過去の生産条件に戻った際、精度がゼロベースに劣化してしまうため非常に危険です 。
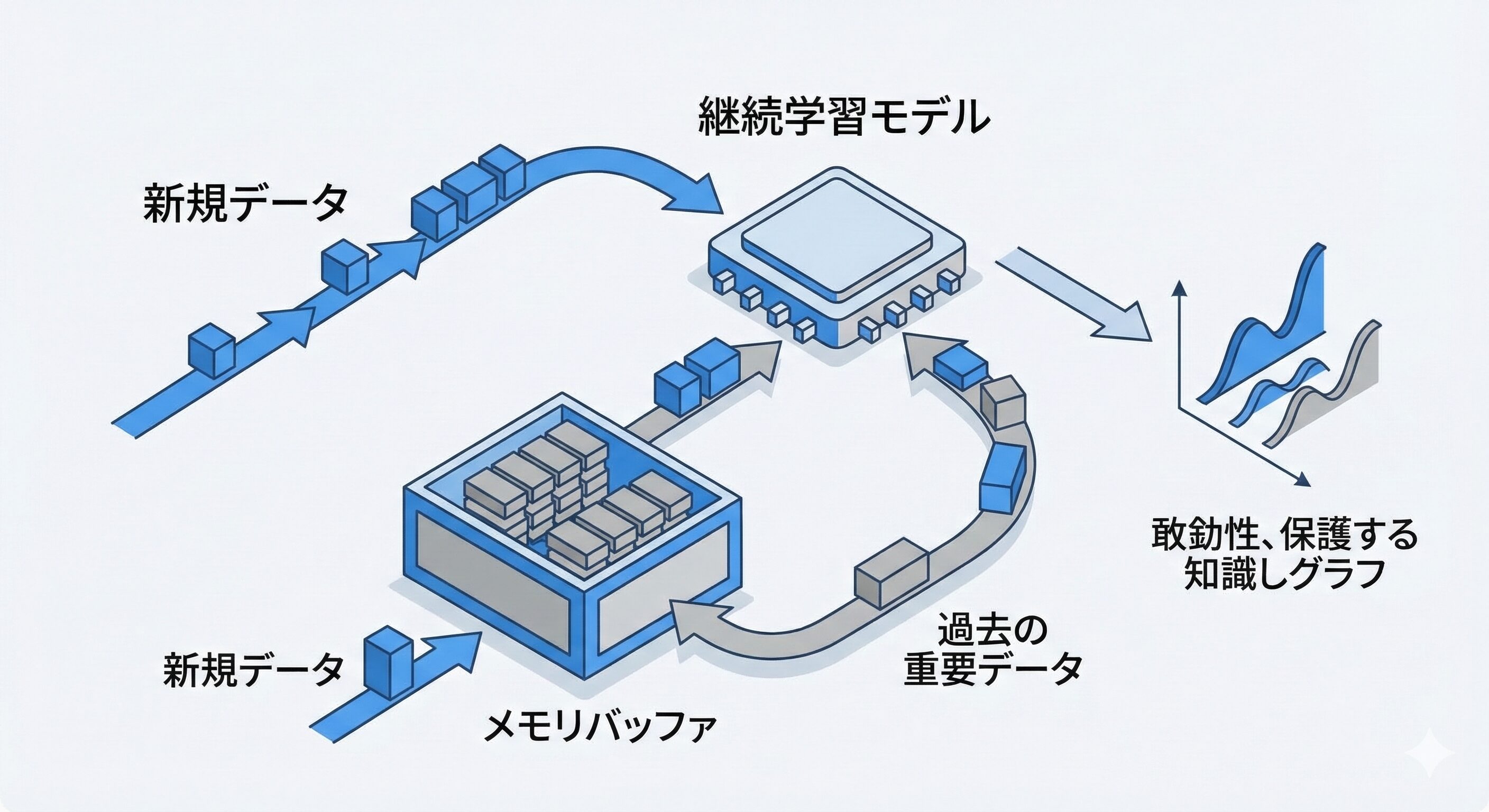
継続学習におけるリハーサル・メモリバッファの仕組み
これを回避する枠組みが「継続学習」です 。専用のメモリバッファに過去の重要なプロセスデータを保存しておき、新しい概念を学習する際にバッファから過去のデータを抽出して混合し、同時に学習させます 。これにより新しい知識を獲得しつつ過去のタスクの表現領域を保護できます 。
バッファにどのデータを残すかについては、単純な貯水池サンプリングの限界を克服するため、パラメータ勾配(計算の過程で「どの方向に数値を修正すれば誤差が減るか」を示す、数学的な坂道の傾きのような情報)の特徴からデータの多様性を最大化するようなインテリジェントなサンプル選択戦略の導入が最先端の研究で進められています 。
物理情報ハイブリッドモデルとサイバーフィジカルシステム(CPS)への統合
純粋な機械学習アルゴリズムは、過去の履歴データセットの範囲内において複雑な非線形パターンを抽出することには極めて長けています 。しかし、データに表れていない未知の領域に対する外挿能力(外挿:過去に経験したことがない極端な数値範囲について、モデルが勝手に推測して答えを出してしまうこと)を持たないという致命的な弱点があります 。現実のプラント運用において、データは安全かつ安定的な限られた操作領域でのみ収集されます 。
そのため、未経験の極端な運転条件や機器の突発的な劣化時に機械学習モデルを適用すると、予測値が質量収支やエネルギー収支といった物理法則から著しく逸脱してしまう危険性を孕んでいます 。プロセスシステム工学ではこの現象を「プラント・モデル・ミスマッチ」と呼びます 。機械学習は統計的な相関関係を見出すことはできても、因果関係を自律的に理解しているわけではないためです 。
この構造的限界を克服し、機械学習の高次元データ解析能力と決定論的な物理法則を融合させる次世代のパラダイムが「物理情報ハイブリッドモデル」です 。ハイブリッドモデルは、結合メカニズムによって主に2つのアーキテクチャに分類されます 。
一つ目の「直列アプローチ」は、第一原理方程式の構築において不確実性の高い内部パラメータ(複雑な反応速度定数や熱伝達係数など)をデータ駆動型モデルで予測し、その結果を物理法則に基づく連立微分方程式系に入力して最終状態を計算する情報の流れを持ちます 。最終出力が必ず物理法則を満たす方程式を経由するため、未知の領域に対する外挿性が極めて高いことが最大の長所です 。
二つ目の「並列アプローチ」は、単純化された第一原理モデルでプロセスの巨視的なベースラインを予測し、実際の観測値との間に生じる残差を機械学習アルゴリズムが並列に予測して補正する構造です 。意図的に計算負荷を軽くできるため、リアルタイム性が要求されるモデル予測制御(MPC)の内部モデルとして極めて適しています 。
PINN(物理情報に基づくニューラルネットワーク)による革新
従来のハイブリッドモデルが物理方程式と機械学習を独立したモジュールとして結合していたのに対し、ディープラーニングのネットワーク構造内部に直接物理法則を埋め込むブレイクスルーとして登場したのが「物理情報に基づくニューラルネットワーク(PINN)」です 。
PINNの革新性は、学習プロセスをガイドする損失関数の再定義にあります 。通常のニューラルネットワークはデータ損失のみを最小化しようとしますが、PINNは観測データとの誤差を示すデータ損失に加え、支配的な偏微分方程式の残差を評価する物理損失と、境界条件・初期条件への適合性を評価する損失を重み付き線形和として定式化します 。
この物理損失を計算する際、深層学習フレームワークが内包する「自動微分」機能を利用することで、メッシュ生成を必要とせず丸め誤差のない極めて精緻な解析的微分値を提供できます 。
現場のエンジニアにとってPINNがもたらす最大の恩恵は、順問題と逆問題を全く同じアーキテクチャ内でシームレスに解決できる点にあります(原因から結果を導くのが「順問題」、結果から原因を特定しようとするのが「逆問題」) 。
現実のプラントでは、限られた観測データから直接測定できない流体の速度場や触媒の失活度合いといった未知の物理パラメータを逆算することが極めて重要になります 。PINNは勾配降下法の過程でネットワークの重みと同時に未知の物理パラメータをも最適化変数として扱い、物理損失項の強力な正則化(モデルが複雑になりすぎないようにわざと制限をかけ、過学習(前述)を防ぐためのテクニック)によって、スパースでノイズの多いデータからでも物理的に妥当な解へ収束させることが可能なのです 。
5CアーキテクチャによるCPSへの実装
ハイブリッドモデルやPINNといった高度な推論エンジンは、プラント内の単独ソフトウェアにとどまらず、「サイバーフィジカルシステム(CPS)」というインフラストラクチャの中枢として統合されることで自律的なループを完成させます 。CPSとは、センサー網から得られた物理空間のデータをサイバー空間と緊密に結合し、得られた最適解を再び物理空間へフィードバックするシステムです 。これを実装するための標準フレームワークが「5Cアーキテクチャ」です 。
Level 1(Connection):プラント内の機器から生データを収集し、OPC UAやMQTT(IoT機器などでよく使われる、データ通信量が少なくて済む軽量な通信プロトコル)といった通信プロトコルを用いてサイバーシステムへ送信します 。
Level 2(Conversion):ノイズの多い生データから、ソフトセンサーを用いて測定困難な品質パラメータや機器の健全性指標を推論し、意味のある情報へと変換します 。
Level 3(Cyber):情報を集約し、PINNなどを駆動させてプラント全体を仮想的にモデル化するデジタルツインを形成します 。
Level 4(Cognition):デジタルツインを利用したWhat-ifシミュレーションを実行し、最適な解決策や意思決定の支援を提示します 。
Level 5(Configuration):意思決定に基づき、物理空間の制御システムへコマンドを送信し、システムを自律的に再構成します 。
デジタルツインの5段階の成熟度とWhat-ifシミュレーション
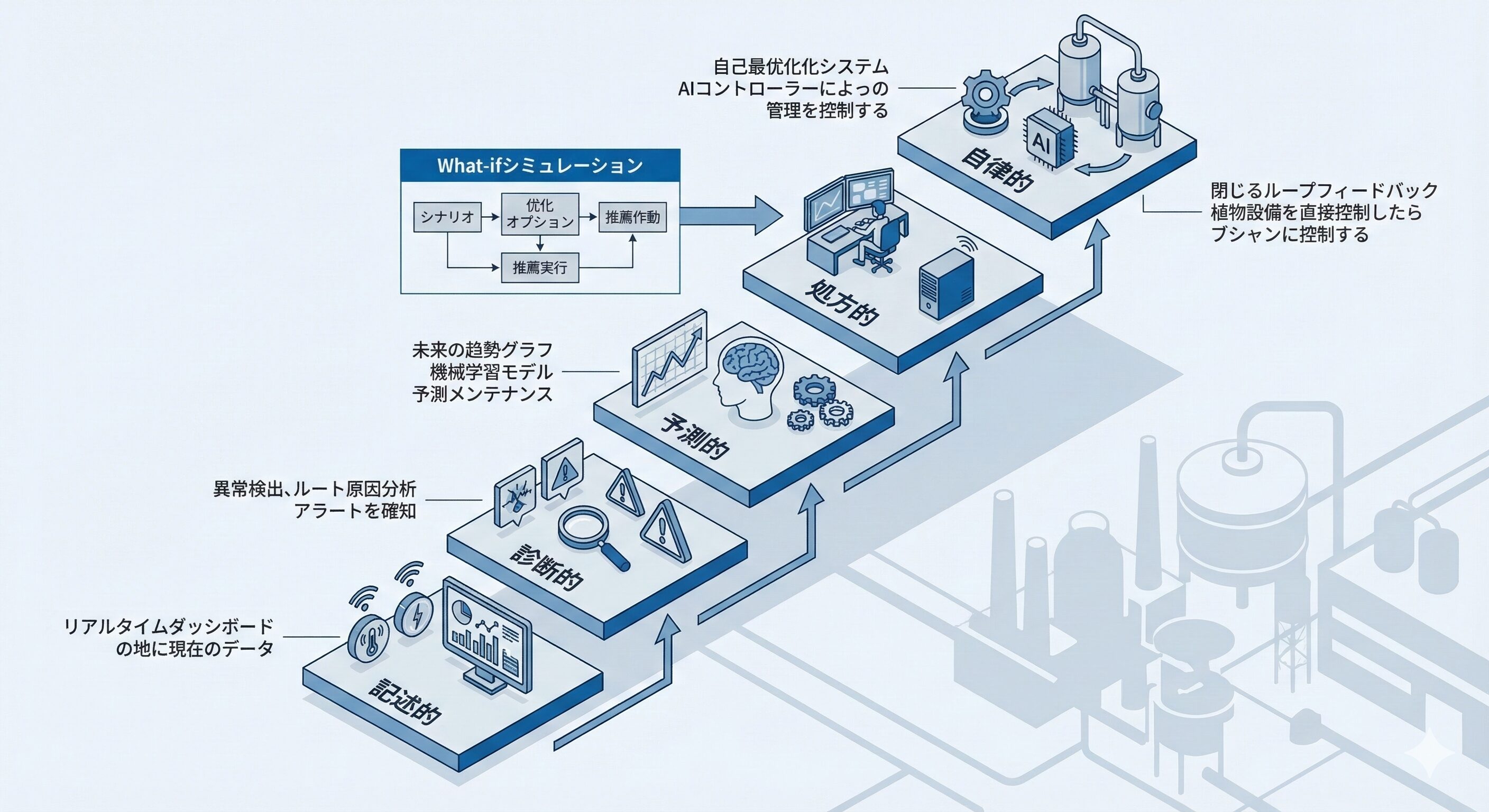
デジタルツインの5段階の成熟度モデル
CPSのCyber層の中核となるデジタルツインは、単なる3Dの視覚的表現ではなく、物理資産の内部状態を仮想空間上でリアルタイムに模倣する生きた動的モデルです 。実装される機能の複雑さに応じて、5段階の成熟度レベルに分類されます 。
レベル1の記述的ツインは現在の状態を視覚的に集約するのみですが、レベル2の診断的ツインへと進むと異常の根本原因を自動で特定するようになります 。レベル3の予測的ツインでは将来の状態を予測し、予兆保全のトリガーを提供します 。
特筆すべきはレベル4の処方的ツインにおける「What-ifシミュレーション」の能力です 。
例えば製油所の触媒改質装置において、上流から投入されるナフサ原料の組成が突発的に変化し、脱硫反応による温度暴走の危険が生じたとします 。従来のフィードバック制御では規格から逸脱した後にしか対処できませんが、デジタルツインは「もしこの組成の原料を投入した場合、反応器内の温度分布はどう変化するか」を瞬時に仮想空間でシミュレーションし、反応器入口温度の最適な低下幅を事前に導き出して処方します 。
環境インフラである廃水処理施設においても、大雨による汚濁負荷の倍増に対し、エアレーション強度の最適な調整を実際のコンプライアンスを危険に晒すことなく事前にテストすることが可能です 。
そして最終段階であるレベル5の自律的ツインに到達すると、これらの処方的な最適化プロセスが人間の介入なしにリアルタイムで実行され、制御システムへ自動コマンドとして送信されるようになります 。AIと物理情報ハイブリッドモデルが環境変動を感知してプロセスの自己補正を継続するこの姿こそが、完全に自律化された予測制御を実現し、持続可能性と強靭な回復力を備えたインダストリー5.0のビジョンを体現する中核技術なのです 。
記事のまとめ
-
ソフトセンサーは、物理的な分析計が抱える測定遅延や高額な維持コストという制約をソフトウェアアルゴリズムで解消し、リアルタイムな品質監視と高度なフィードバック制御を可能にするインダストリー4.0の中核技術です。
-
高精度な推論を実現するためには、AIアルゴリズムの選定以上にデータの前処理が重要であり、HampelフィルタやCARS-PLSといった手法を用いて、プラントデータ特有のノイズや見せかけの相関を徹底的に排除し、真の因果関係をモデルに学習させる必要があります。
-
プラントは触媒の失活や配管の汚れにより絶えず変化(概念ドリフト)するため、一度構築したモデルを放置せず、JIT学習や継続学習といった適応型アルゴリズムを組み込み、モデルの劣化を自動検知して常に最新の状態に保つ運用設計が不可欠です。
-
最終的には、データ駆動型AIに質量収支やエネルギー収支といった物理法則を埋め込む「物理情報ハイブリッドモデル(PINNなど)」へと進化させることで、未知の運転領域でも破綻しない強靭なデジタルツインを構築し、プラントの自律的な最適化を目指すことが重要です。

コメント